

This is the first in a series of posts about the 8 Fallacies of Distributed Computing, a set of common misconceptions or false assumptions that are often made when building distributed systems. Keeping these fallacies in mind when building your cloud services, as well as your front-end clients can drastically improve your user experience and your developer experience. You can read the rest of the series here
With today’s modern network infrastructure it’s often easy to forget that the Internet, and all of our local networks, are a Best-effort delivery service. The IPv4 protocol used to get datagrams from point A to point B can suffer packet loss, arbitrary delays, corruption, or duplication of packets. TCP builds on top of this and goes some way to solve these issues, but requires trade-offs in latency to achieve. Even with the safeguards like retransmission, slow-start, etc, there is no guarantee that hardware failure won’t result in a failed requests. This issue is even more apparent when working with mobile devices, where a user may be travelling on a train with spotty reception, or working on WiFi with dozens of other clients all competing for bandwidth.
A prime example of this was in December 2021 when Amazon Web Services suffered multiple network device failures simultaneously causing not only their own services to be affected, but also caused issues for Netflix, Disney+, and hundreds of other companies around the world. Similar issues with major providers like AWS, CloudFlare, and GCP have caused outages across the Internet in the past.
Whenever you’re working with code that makes a call to an external system, whether it’s a call to disk, a device running on your local network, another server running within your cloud environment, or your CDN, it’s important to remember one thing; it’s not a question of if a request to an external system will fail, but a question of when, and how often.
So how do we protect against these issues? Where do we start?
Dealing with Failures in Requests
When working with an external service there’s some simple patterns you can use to try and recover from failure when they occur
-
Use Retries, with Exponential Backoff and Jitter to deal with 5XX responses (4XX errors are client errors, and retrying is unlikely to fix them)
-
Wrap every external call (including calls to disk) in a try/catch, and have a plan for dealing with the failure within your app beyond printing an error log
By ensuring that the calls you make to these external systems are able to be caught and retried transient errors within the system can be overcome without requiring the user to know anything ever went wrong (except for a slightly longer response time). By adding Exponential Backoff and Jitter we can prevent errors across all of your clients causing your server to be overwhelmed. One thing to keep in mind with the retries is ensuring an upper limit, so it’s not just trying indefinitely while your user waits.
User Experience for Failures
When working with any client that makes calls to an external resource, be it network or disk, it’s important to design the interactions with failure in mind. It’s not just about making sure you add try/catches around all your external calls (although, again, you definitely should!) but also thinking about your User Experience for Failures.
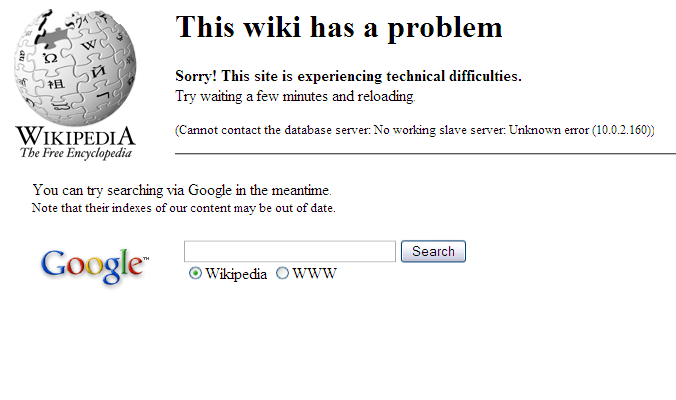
Above is a fairly good example of a User Experience for Failure. It provides a visually on-brand response that not only explains an action that the user can take (try again in a few minutes) but also gives them the option of using Google Search instead. I’d argue that telling the user a database error occurred is irrelevant, it’s not like the user is going to fix it and the engineers should have metrics and monitoring to tell them something went wrong, but it still provides something more than the default browser error page.
Even before you show the user a failure screen though, there are other ways to ensure a good user experience. If you can, make the request non-blocking i.e. allow the user to continue using your app and then use a push notification with a pop-up to tell them the request succeeded or failed, and if it failed give them a link to go back and sort out the issue.
Architecting for Success
Typically, a lot of these problems can be avoided by looking at your Cloud architecture. One of the simplest ways to reduce the chance of a request failing is to reduce the number of network calls being made by your cloud platform. In practice this generally means preventing daisy-chained requests (i.e. service A calls service B calls service C) within your sytem. When a service is unable to satisfy a request without making requests to other systems it means there is a hard link between those services, one can’t work without the other, meaning that what you have isn’t a decoupled set of microservices, it’s a distributed monolith that brings in the worst of both worlds.
This can’t always be avoided, but architecting an eventually consistent system with data replication greatly reduces the number of requests required to complete a request. This has the trade-off of requiring data duplication (which should be fine, as storage is cheap) but also introduces the much more challenging problem of ensuring your data is correct (especially if you require consistent reads/writes). If you’re finding it difficult to reduce the number of requests you make then it may be time to consider the boundaries of your service.
Conclusion
When working with any software that makes connections over a network of any type, it’s important to remember that at some point those calls will fail, and to build not only your cloud architure, but your clients and user experience to cope with those inevitable failures.

Comments